


Jan 2, 2026
Why Avoiding Conflict Costs You More
Read More







Artificial intelligence fundamentally relies on massive amounts of data to learn, adapt and make accurate predictions. Historically, tech companies gathered this information by collecting massive troves of personal information and storing it in centralized cloud servers. This approach created significant friction between the need for smarter algorithms and the basic human right to privacy. Consumers and regulators alike now demand better protection for sensitive information.
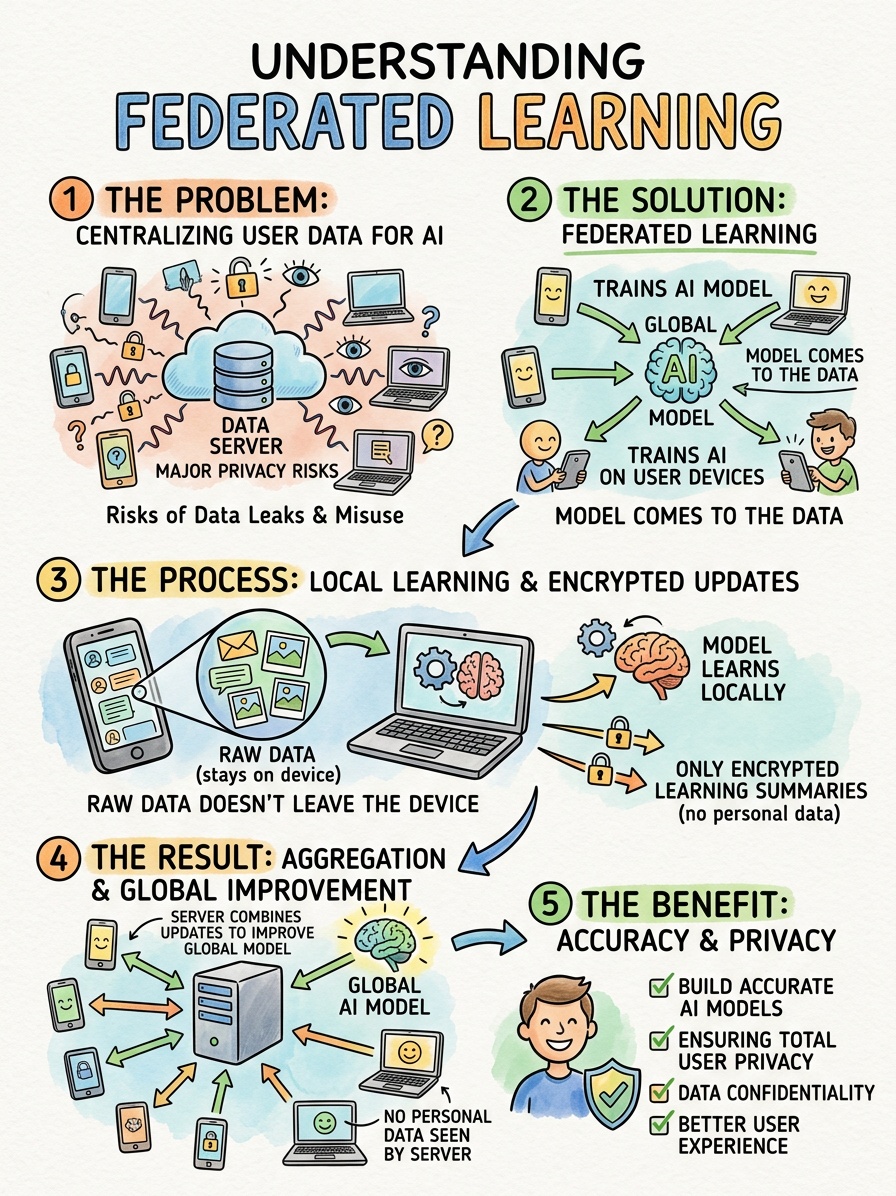
Data scientists have developed a powerful solution to this exact problem. They call it federated learning. This decentralized machine learning approach allows a central model to train across multiple edge devices holding local data samples. Most importantly, the system accomplishes this without ever exchanging or centralizing the raw data.
This article explores the mechanics, benefits, challenges and applications of federated learning. You will learn how modern AI systems process information directly on your smartphone, hospital server or smart car. We will uncover how decentralized machine learning protects user privacy while reducing bandwidth consumption. By understanding these concepts, you can better navigate the future of artificial intelligence and data security.
To understand federated learning, we must first look at how traditional machine learning operates. Standard AI training requires a centralized approach. Developers pull raw data from thousands or millions of users into a single, massive database. They then train the algorithm on that centralized server.
Federated learning completely flips this architecture upside down. Instead of bringing the data to the model, this approach brings the model to the data.
The process begins with a central server hosting a baseline artificial intelligence model. This global model possesses a basic understanding of the task at hand, whether that involves recognizing speech or predicting text. The central server sends a copy of this global model out to thousands of participating edge devices.
Edge devices are the physical hardware pieces operating at the outer edge of a network. They include your smartphone, your laptop, IoT sensors and autonomous vehicles. These devices hold unique, highly specific local data samples generated by your daily activities.
Once the edge device receives the global model, it begins training locally. The model learns directly from the data stored on that specific device. If the model aims to improve predictive text, it studies exactly how you type, which slang you use and the specific phrases you prefer.
Because this training happens locally on your device's processor, your personal text messages never leave your phone. The raw data remains completely isolated and secure. The model simply learns the underlying patterns and adjusts its own internal parameters based on your unique behavior.
After the local training session concludes, the edge device summarizes what it learned. It creates a small data packet containing mathematical updates, often called weights or gradients. The device sends only this mathematical summary back to the central server.
The central server receives these mathematical updates from thousands of different devices simultaneously. It averages these updates together using a process called federated averaging. The server then applies this aggregated knowledge to the central model, making it smarter and more accurate. Finally, the server pushes this newly improved global model back out to the edge devices, and the cycle repeats.
This decentralized machine learning approach offers massive advantages over traditional centralized systems. By fundamentally changing how data moves through a network, federated learning solves several major bottlenecks in artificial intelligence development.
The most significant benefit of federated learning is the profound enhancement of data privacy. Because the raw data never leaves the local device, hackers cannot intercept it during transmission. Furthermore, the central server never stores a giant database of sensitive user information.
If a cybercriminal manages to breach the central server, they will not find any personal emails, medical records or private photos. They will only find a collection of abstract mathematical weights. This architecture complies seamlessly with strict data protection regulations, allowing companies to build powerful AI tools without violating user trust.
Moving massive amounts of data across the internet costs a tremendous amount of money and energy. Uploading thousands of high-resolution images or hours of video footage to a central server consumes significant bandwidth. It also introduces severe latency, slowing down networks and degrading the user experience.
Federated learning drastically reduces this burden. Instead of uploading gigabytes of raw data, the edge device only uploads a few kilobytes of mathematical updates. This hyper-efficient communication protocol allows developers to train complex models over slow or unstable internet connections. It also frees up valuable bandwidth for other essential network operations.
Federated learning is no longer just a theoretical concept. Tech giants and research institutions actively deploy this technology to solve complex problems across various industries.
The healthcare industry possesses some of the most valuable data in the world. Artificial intelligence could use this data to discover new drugs, predict disease outbreaks and improve cancer detection. However, strict patient privacy laws like HIPAA prevent hospitals from sharing raw patient records with outside tech companies or even with other hospitals.
Federated learning provides the perfect solution. A central medical AI model can travel to multiple different hospitals. It trains locally on each hospital's private patient database, learning to identify tumors on X-rays or predict patient readmission rates. The model absorbs the collective knowledge of dozens of medical institutions without ever exposing a single patient's identity.
You likely use federated learning every single day without realizing it. Mobile operating systems heavily rely on this technology to power features like predictive keyboards and voice assistants.
When you type on your smartphone, the local AI model learns your specific vocabulary and typing habits. It sends mathematical summaries of your typing patterns back to the central server. The server combines your updates with updates from millions of other users. This collaborative process allows the company to improve the global predictive text algorithm for everyone, without ever reading anyone's actual text messages.
Self-driving cars generate massive amounts of data every second. They record video footage, radar signatures and driver inputs as they navigate complex city streets. Uploading all this raw data to a central cloud server in real time is technically impossible.
Instead, autonomous vehicle manufacturers use federated learning. The car's onboard computer analyzes the driving data locally. It learns how to better recognize pedestrians, navigate construction zones and handle severe weather. When the car connects to Wi-Fi, it sends its learned updates back to the manufacturer. The global driving model improves and the manufacturer sends a safer, smarter algorithm to the entire fleet of vehicles.
While federated learning offers incredible potential, it also introduces unique engineering hurdles. Decentralizing the training process creates several complex challenges that data scientists must actively manage.
In a centralized data center, developers control the hardware perfectly. Every server possesses the exact same processing power and memory. In a federated network, the hardware varies wildly.
One user might train the model on a brand new, ultra-fast smartphone, while another user attempts to train it on a five-year-old device with a degraded battery. Edge devices also frequently drop offline due to poor cellular service or dead batteries. Data scientists must design federated learning systems that can gracefully handle these hardware discrepancies. The central server must patiently wait for slower devices or drop them from the training round without ruining the global model.
In standard machine learning, developers ensure the training data is carefully balanced and randomized. In federated learning, the data is completely dictated by the specific user. We call this Non-IID data, which stands for non-independent and identically distributed.
For example, a predictive keyboard model might train on the phone of someone who only types in Spanish, while another phone only produces English text. A facial recognition model might train on a phone owned by a person who only takes photos of their cat. If the central server does not carefully manage these extreme variations, the global model can easily become biased or confused.
While federated learning protects raw data, it opens the door to new security vulnerabilities. Because the central server accepts mathematical updates from thousands of unknown edge devices, a malicious actor can attempt to sabotage the system.
Hackers can deliberately feed bad data to the local model on their device. They can then send toxic updates back to the central server, hoping to corrupt the global algorithm. This tactic is known as a data poisoning attack. Security engineers must implement robust defense mechanisms to identify and reject suspicious updates before they infect the broader network.
Federated learning represents a massive leap forward for artificial intelligence. By decentralizing the training process, we can build smarter, more capable algorithms without sacrificing our fundamental right to privacy.
This approach proves that tech companies do not need to hoard our raw data to deliver innovative products. As edge devices grow more powerful, federated learning will expand into smart homes, wearable health trackers and financial systems. We are entering an era where collective intelligence thrives alongside strict data protection.
To prepare for this shift, organizations should review their current machine learning pipelines. Explore how decentralized training can reduce your data storage costs and eliminate severe compliance risks. Embrace the technology that allows you to learn from your users while leaving their personal lives completely untouched.




