


Jan 2, 2026
Why Avoiding Conflict Costs You More
Read More






When you speak to a voice assistant, translate a webpage, or use facial recognition to unlock your phone, you interact with highly complex artificial intelligence. These systems seem to possess a magical ability to learn and adapt. Yet, beneath the surface of these deep learning models lies a strict, mathematically elegant process. The true engine driving modern artificial intelligence is an algorithm called backpropagation.
Before we can trust neural networks to drive cars or diagnose diseases, we must understand exactly how they learn. Training a neural network requires finding a way to correct its mistakes. If AI misidentifies a stop sign as a speed limit sign, the system needs a mechanism to adjust its internal wiring so it does not make the same error twice.
This article explores the mechanics, significance and real-world applications of backpropagation in artificial intelligence. You will learn how neural networks process information, how they measure their own failures and how backpropagation systematically adjusts internal weights to minimize errors. By understanding this foundational algorithm, you gain a clearer picture of how machine learning actually works.
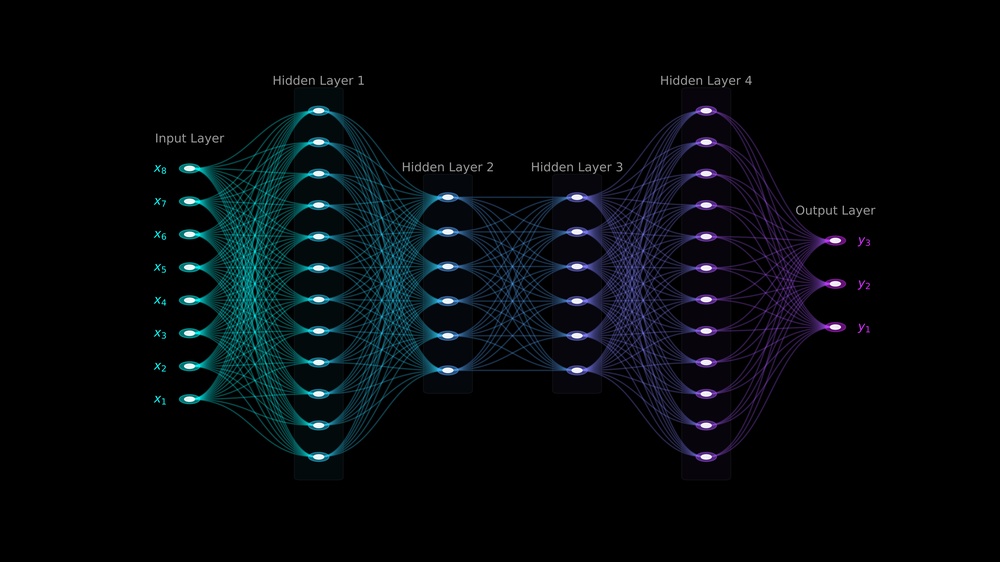
To understand backpropagation, we must first look at the structure of an artificial neural network. These networks consist of interconnected layers of artificial neurons or nodes. A standard network features an input layer, several hidden layers in the middle and an output layer.
Each connection between these neurons carries a specific "weight." You can think of a weight as a volume dial. If the weight is high, the signal passes through strongly. If the weight is low, the signal fades. When you feed data into the neural network, the information flows from the input layer, through the hidden layers and out to the output layer. Data scientists call this journey the "forward pass."
During the forward pass, the network makes a prediction based on its current, often randomized, weights. For example, if you train the network to recognize images of cats, the forward pass processes the pixels and outputs a guess. Initially, the network will perform terribly. It might look at a picture of a cat and confidently predict it is a toaster.
When the neural network makes a wrong prediction during the forward pass, we need a way to quantify exactly how wrong it was. This brings us to a crucial concept: the loss function.
The loss function acts as the ultimate grader for artificial intelligence. It takes the network's prediction and compares it to the actual, correct answer. If the network guesses "toaster" but the true label is "cat," the loss function calculates a very high error score. If the network guesses "dog," the error score drops slightly, because a dog shares more visual traits with a cat than a toaster does.
The primary goal of training any machine learning model is to minimize this loss function. You want the error score to be as close to zero as possible. However, the neural network cannot simply tell itself to "do better." It needs a specific set of instructions telling it exactly which volume dials, that is the internal weights, it needs to adjust to lower the error.

This is where backpropagation, short for "backward propagation of errors," steps in to save the day. Once the loss function calculates the total error at the output layer, backpropagation sends that error signal backward through the network.
The algorithm calculates the gradient of the loss function with respect to every single weight in the network. In simple terms, the gradient tells the system two vital pieces of information about each weight. First, it tells the network the direction to turn the dial (should the weight increase or decrease?). Second, it tells the network the magnitude of the turn (should it adjust the weight by a massive amount or just a tiny fraction?).
Backpropagation accomplishes this massive calculation using a calculus principle called the chain rule. Because neural networks feature multiple hidden layers stacked on top of each other, an error at the final output layer stems from a complex chain of mathematical operations.
The chain rule allows the algorithm to unpack these operations step by step, starting from the end and moving to the beginning. It asks a simple question at each node: "How much did this specific weight contribute to the final error?"
If a specific weight caused a massive chunk of the final error, backpropagation calculates a steep gradient, instructing the system to change that weight drastically. If a weight barely affected the outcome, the algorithm calculates a shallow gradient, leaving the weight mostly alone.
Backpropagation calculates the gradients, but it does not physically change the weights itself. It hands those mathematical blueprints over to an optimization algorithm, most commonly Gradient Descent.
Gradient Descent uses the gradients provided by backpropagation to update the weights. Picture a blindfolded person standing on a rugged mountain, trying to find the lowest valley. Backpropagation acts as their foot, feeling the slope of the ground (the gradient). Gradient descent acts as the step they take down the hill. By repeating this forward pass, error calculation, backward pass and weight update thousands of times, the neural network slowly steps down the mountain until it reaches the valley of minimal error.
You might wonder why this specific algorithm matters so much to the history of technology. Before backpropagation became widely adopted, the field of artificial intelligence suffered a massive stagnation known as the "AI Winter."
Early neural networks, called perceptrons, only had an input layer and an output layer. They could solve basic linear problems, but they completely failed at complex, non-linear tasks. Researchers knew that adding hidden layers could solve these complex problems. Unfortunately, nobody knew how to train a network with hidden layers. Without a way to calculate how the hidden neurons contributed to the final error, deep learning remained impossible.
In the 1980s, researchers including Geoffrey Hinton, David Rumelhart and Ronald Williams popularized backpropagation as the definitive solution. By proving that the chain rule could successfully train deep, multi-layer networks, they single-handedly resurrected the field of neural networks. Every major breakthrough in deep learning over the last decade traces its roots directly back to this foundational algorithm.
Because backpropagation serves as the universal training mechanism for deep learning, its applications span virtually every major industry.
Large Language Models (LLMs) rely entirely on backpropagation during their training phase. When developers feed billions of words into a transformer model, the network predicts the next word in a sequence. When it guesses incorrectly, backpropagation calculates the gradients across hundreds of billions of parameters, adjusting the network until it can generate fluent, human-like text.
Convolutional Neural Networks (CNNs), which power facial recognition and autonomous driving, also depend on backpropagation. In the medical field, researchers train CNNs to detect early signs of cancer in MRI scans. The forward pass makes a diagnosis, the loss function evaluates the accuracy against a doctor's confirmed diagnosis and backpropagation adjusts the filters until the AI can spot micro-tumors invisible to the human eye.
Banks and investment firms use deep learning to predict stock market trends and detect fraudulent transactions. By processing years of historical market data, the neural network learns to spot hidden financial patterns. Backpropagation ensures that when the model makes a poor financial prediction during training, it immediately corrects its internal logic, eventually producing highly robust forecasting tools.
While backpropagation dominates machine learning, it is not flawless. As neural networks grow deeper, the algorithm faces significant structural challenges.
The most famous issue is the "vanishing gradient problem." When backpropagation calculates gradients through a very deep network with dozens of hidden layers, the error signal can shrink exponentially as it moves backward. By the time the signal reaches the earliest layers, the gradient becomes so microscopic that the weights barely change at all. The front of the network stops learning completely.
While modern activation functions and architectural changes have largely mitigated this issue, backpropagation remains incredibly computationally expensive. Calculating gradients for trillions of parameters requires massive server farms running specialized graphics processing units (GPUs). This heavy energy consumption drives researchers to seek more efficient alternatives.
Furthermore, cognitive scientists frequently point out that human brains do not use backpropagation. Our biological neurons do not freeze, calculate a global error and send signals backward to adjust synapses. This realization sparks an ongoing debate: if we want to achieve true Artificial General Intelligence (AGI), do we need to abandon backpropagation and discover an algorithm that closer mimics human biology?
Despite its computational costs and biological differences, backpropagation remains the undisputed champion of artificial intelligence training. It transformed neural networks from academic curiosities into powerful engines driving global industries.
By understanding how this algorithm calculates the gradient of the loss function and systematically adjusts internal weights, you demystify the "magic" of artificial intelligence. You recognize AI not as an unexplainable mind, but as a rigorous mathematical system striving to minimize its own errors.
As developers continue to build larger and more complex models, the core principles of backpropagation will continue to guide their success. Whether we are predicting the weather, discovering new pharmaceuticals or conversing with a chatbot, we owe the intelligence of our machines to the elegant math of the backward pass.




